Hadoop HDFS Architecture and Design
Fault-tolerant:
HDFS is highly fault-tolerant and is designed to be deployed on multiple nodes so that if one node fails the other node is available. HDFS is good for applications that have large data sets, the throughput is very high in HDFS design. With some additional setup, HDFS can accommodate live streaming ability and real time data processing.
NameNode:
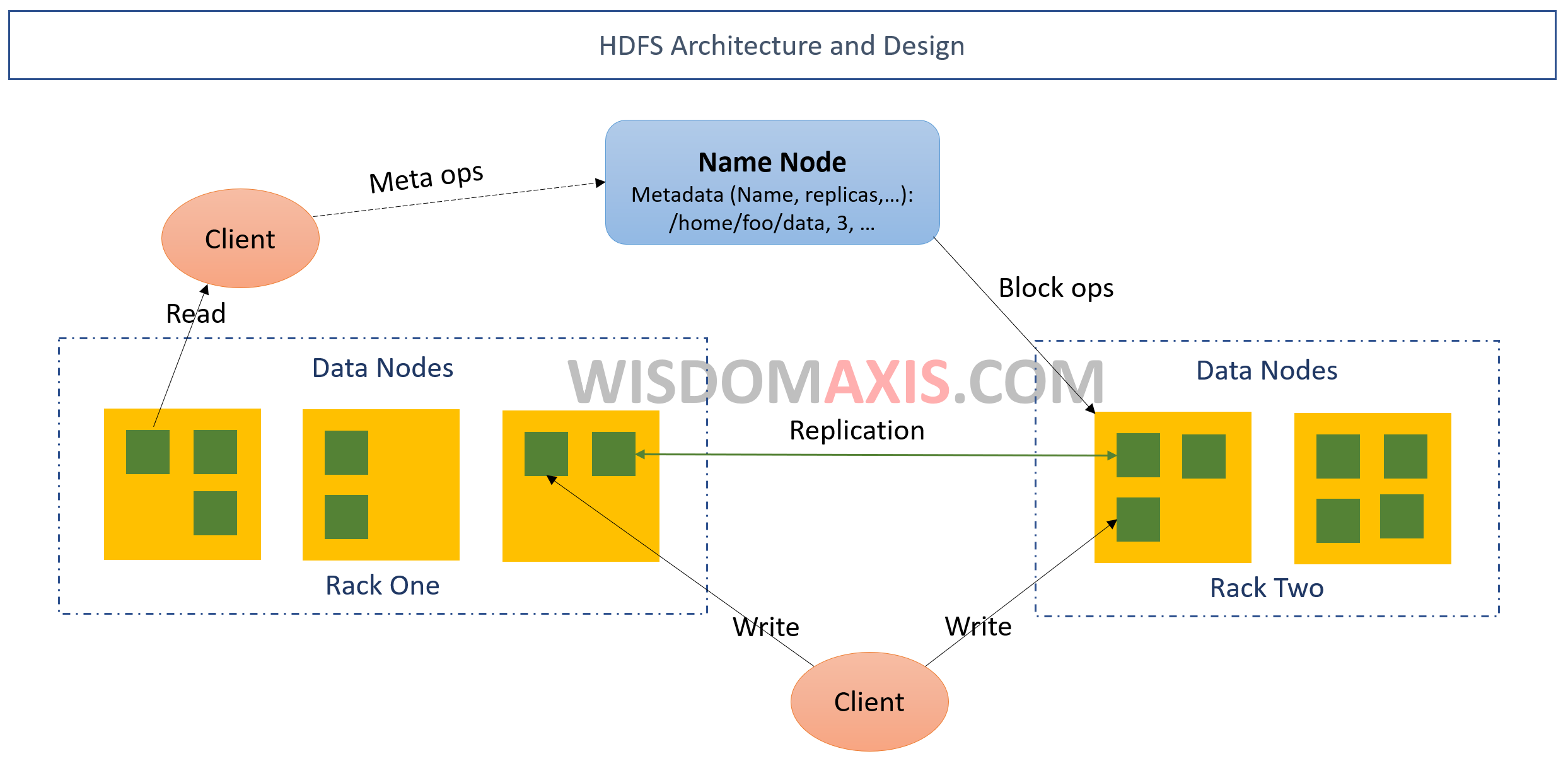
It is repository of HDFS metadata. The user data never flows through the NameNode, this design protects the metadata without corrupting the Name node. The NameNode acts as an arbitrator. The NameNode executes file system operations such as opening, closing and renaming of files and directories. HDFS cluster consists of a single NameNode, a master server that manages file system. Also, the mapping of blocks to DataNodes is determined by the NameNode.
DataNode:
HDFS cluster consists of several DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. NameNode determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
Data Replication:
To maintain the fault tolerance, the replication is an important process. HDFS can store very large files across machines in a large cluster. It stores each file as a sequence of blocks. The size of the block and replication factor are configured per file. In general replication factor is 3.x and block size is 128 MB. The NameNode makes all decisions regarding replication of blocks. It periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the cluster. Block report contains all blocks on a DataNode. Heartbeat to know whether DataNode is functioning or not. ...Click here for full details